
What languages are supported?
We currently support:
- Arabic
- Catalan
- Czech
- Danish
- Dutch (Belgium)
- Dutch (Netherlands)
- English (Australia)
- English (Canada)
- English (Scotland)
- English (United Kingdom)
- English (United States)
- English (Northern England)
- Finnish
- French (France)
- French (Canada)
- German
- Greek
- Italian
- Norwegian
- Polish
- Spanish (Spain)
- Spanish (United States)
- Swedish (Sweden)
- Turkish
- Portuguese (Portugal)
- Portuguese (Brazil)
More to come – Other languages from Acapela’s language portfolio will be added in the future.
How do I log into the MOV recorder application?
To log into the online MOV recorder, use the same login/password than the one you use to login onto the ‘My-Own-Voice’ website.
How do I get started with 'My-Own-Voice'?
You need to contact us via the ‘Start now’ section to get login credentials, and then choose your language and start the recording.
What are the requirements for a custom message?
Please have a look to the custom message guidelines and tips
How do we prevent issues between the microphone's default settings in conjunction with the use of the Acapela Recorder application?
The MOV Recorder must have total control over the microphone function. On the latest Windows and MAC OS X operating systems, the default settings might possibly prevent the MOV Recorder from working properly.
On Windows 10 and higher, you may verify the following:
- In the settings panel (Windows + i) > Privacy > Microphone >
- Ensure that “Allow apps to access your microphone” and “Allow desktop apps to access your microphone” are both on the “ON” position
On MacOS 10.14 and higher:
- On your Mac, go to the Apple menu > System Preferences, click Security & Privacy, then click on Privacy.
- Select Microphone.
- Select the tickbox next to the “Acapela Recorder” app to allow it to access the microphone.
Can I do the recordings at home?
The better the recording quality – the better the resulting computer voice.
An ideal set up would be a professional studio, and someone monitoring your pronunciation.
However, if you do not have the possibility to record in a professional studio, you can do the recording in a quiet room at home at your convenience.
Avoid street and traffic noise, and remove any other source of background noise (e.g. ticking clocks, mobiles, barking dogs, noisy neighbors etc.) to avoid getting them into your recordings.
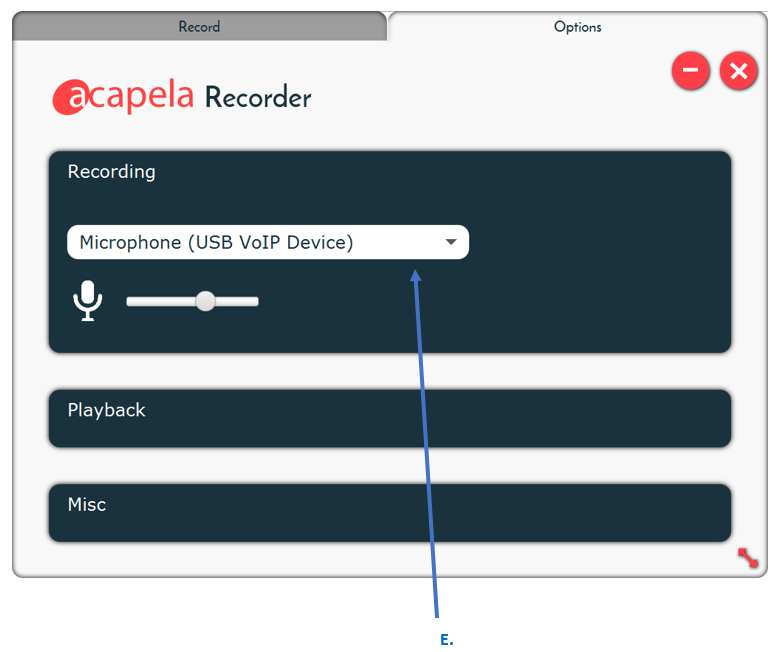
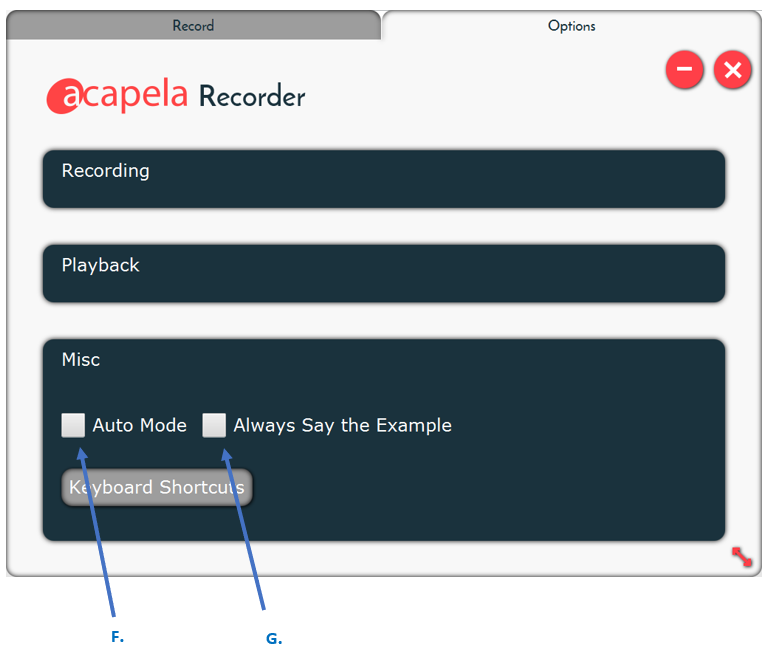
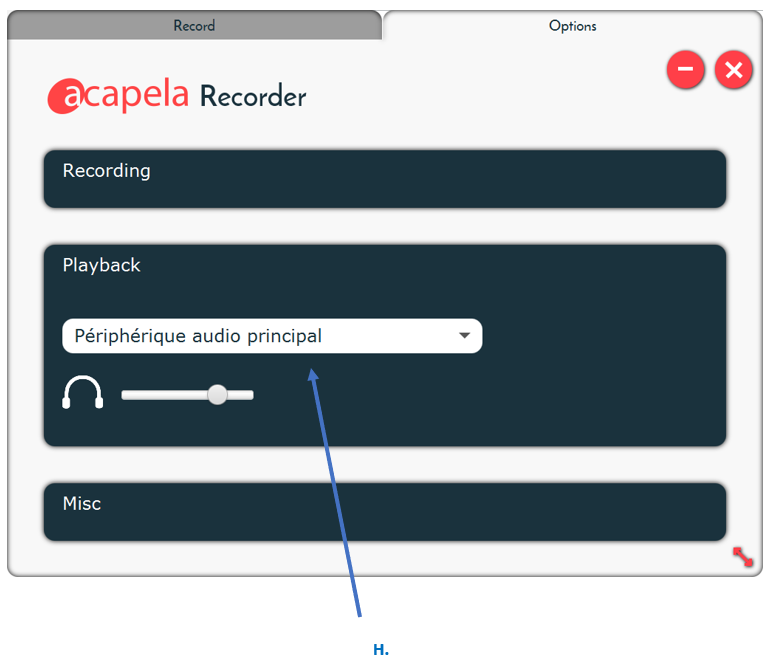
What is the Acapela Recorder option?
From the Options tab of the Acapela recorder, you can:
- Select your input device from the list in E
- Select the auto mode in F (auto mode is a function to read the script automatically and allows the user to record a sentence before moving to the next one)
- Select the vocal/pronunciation guidance mode which reads each sentence before the user begins recording (pronunciation guidance) by checking G
- Select your output device from the list in H
Do I need any special equipment?
To complete the recordings, you will require a good Internet connection and a computer.
You will need a good quality directional microphone (see suggested microphone specifications below). The advantage of a head-mounted microphone is that it allows you to keep more or less the same distance.
Just keep in mind not to breath directly into the microphone.
We do not advise recording with a built-in laptop microphone, because:
- It is difficult to keep a consistent distance from your laptop microphone and to maintain good posture as you speak.
- Built-in microphones are usually omnidirectional and designed to pick up sounds from everywhere, thus also ambient noise!
- They are often of inferior quality compared to the head-mounted ones.
What specification should the microphone have?
As explained in the “What microphone should I use?” section, we always suggest using a head-mounted microphone (headset) to keep the distance between the microphone and mouth constant.
Regarding quality, we suggest that the microphone meets the following specifications:
- Directional Microphone
- Noise cancellation
- Frequency range from 80Hz to 15 000Hz
What microphone should I use?
The recordings can be done from home through our website interface with a headphone set. You can try using a quality directional headset microphone (like e.g. a Sennheiser USB headset, Logitech USB Headset).
Stick to the same distance from your mouth to the microphone and maintain computer volume settings as in the previous sessions.
Avoid making breathing sound directly into the microphone to prevent clipping.
Are Bluetooth microphones recommended for the recordings?
A Bluetooth microphone doesn’t have the sound quality that a corded microphone does and it is not recommended for the usage of the service.
Although it may be acceptable for instances when cords are impractical, such as when recording on the move or when you are at a long distance from your recording device. This often results in disconnections and therefore, alters the quality of the recordings made.
What volume of reading materials do I need to record and to create a voice?
You will need reading materials that reach a volume of 50 sentences to create a voice. The sentences should be phonetically balanced and contain all the sound combinations necessary to synthesize the target language. The synthetic voice will be capable of reproducing any written text.
Can I add my own personal messages, phrases or expressions ?
Yes, you can upload a txt file before starting the recordings with up to 300 personal phrases or expressions to be recorded. Those phrases will be recorded after the Acapela 50-phrase script is recorded. Note that the audio files will be delivered with your synthetic voices package and not as separate audio files.
Those messages (also called banked Messages) are personal and private audio messages created for you and about you, via the My-Own-Voice service. These messages make it possible for loved ones to keep a connection with you using more emotions and expressions together with your synthetic voice.
IMPORTANT NOTE: The custom messages need to be set and uploaded to the My-Own-Voice website before you start the voice banking process for the best experience.
More information about the process in the Upload of custom messages material procedure manual.
How much time will it take to complete the My-Own-Voice recordings?
The number of sentences you will need to record is 50. It may take between 20 to 30 minutes to record the complete set, depending on how efficient you are.
The total set of sentences doesn’t need to be recorded in one session, but can be split over different sessions depending on your available time and voice constraints.
Should I make the recording in one session?
You can record the 50 phrases (or more if you add custom messages) in one session (average between 20-30 minutes) or with multiple sessions, but within a short time interval (e.g : 2 sessions of 15 minutes within 2 or 3 days).
It is always recommended to make the recording within a short time interval to avoid changes in the voice. Our statistics show that recordings completed within 2 or 3 days provide optimal results.
The best scenario is to record all in one session.
How should I speak to get the best text-to-speech quality?
Here is a list of tips for the recording session and on how to improve the voice quality:
- Try to make volume/clipping controlled recordings and use a good quality microphone.
- Keep to the pronunciation in the sound example for each sentence and keep a constant speech rate and voice volume throughout the sessions.
- Well-articulated and steady speech and breathing may give better segmentation results, but keep the pronunciation natural by all means (do not over pronounce separate sounds or syllables).
- Keep the same pace and a similar pitch level, intonation, speech rate and voice quality as in previous sessions. E.g. If your nose is blocked, you will sound more nasal. Listen to your own recordings from previous sessions prior to the start of the new one and stick to your own voice and microphone settings from the previous sessions.
- Be aware that your TTS will sound relatively similar to the way you choose to speak.
- Exaggerated or very “jumpy” intonation might produce a somewhat mediocre synthesis result.
- You should read a few sentences before the real recording starts, to warm up the voice.
- Avoid big meals during the recordings. Avoid strong sugary or salty snacks/drinks so as not to dry out your vocal chords or cause an abnormal production of mucous that might impair your way of speaking.
- Take enough breaks, drink room-temperature water (before you are actually thirsty), and do not push your voice to the limits (if you are untrained, the voice quality might change as you get tired).
- Warm up your voice, and keep going, while you are “in the flow”.
- Clearing your voice can help, but if you find yourself doing this too often, take a small break or drink some water.
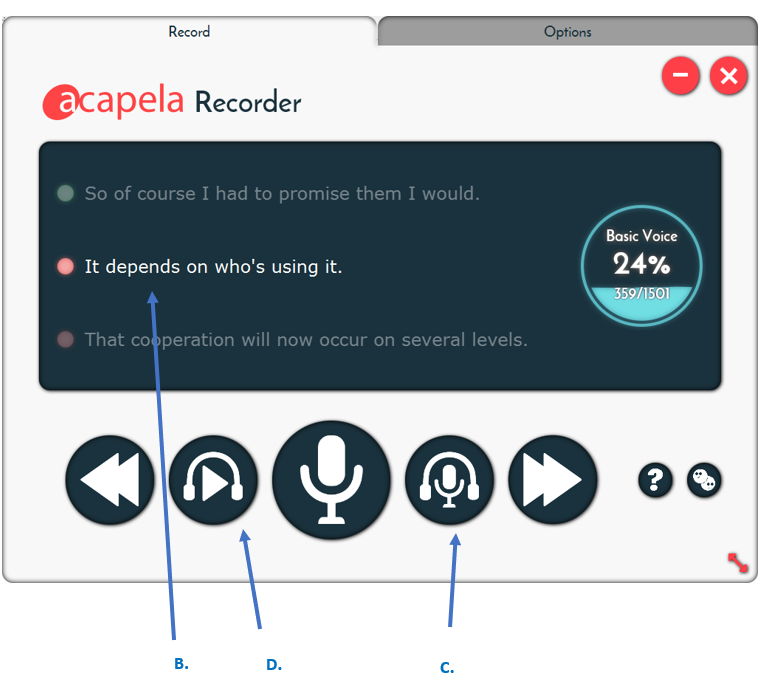
How do I monitor the recording quality?
There are several steps/tips to consider: Keep the same mouth-to-mike distance and computer volume settings across different sessions.
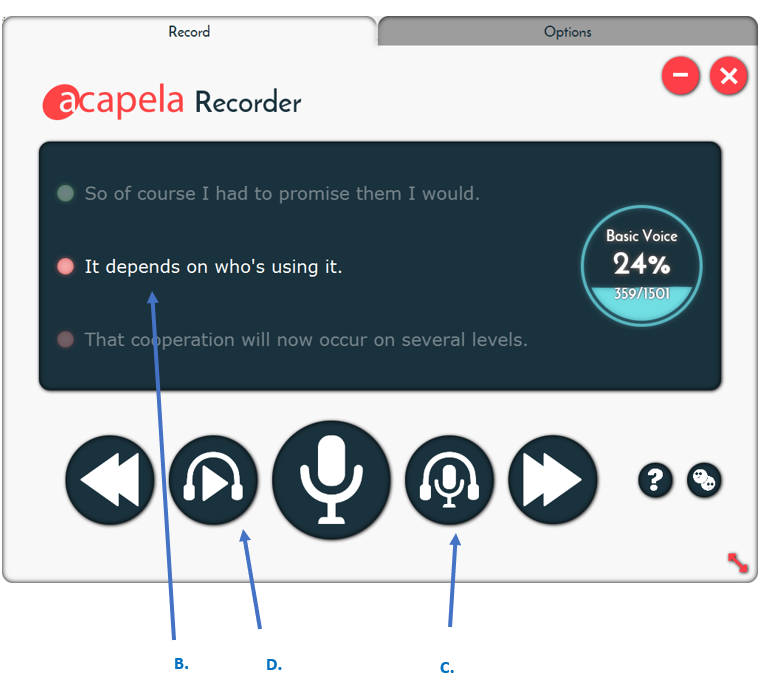
- Calibrate your microphone at the start of the Acapela recorder (A. in the picture below)
- A green light indicates the sentence has been recorded, a yellow light indicates the ongoing recordings and the red light indicates that the sentence has to be recorded. (B. in the picture below)
- You can listen to what you have recorded by pressing C. (available if the file has been saved)
- Listen to the example of standard pronunciation in D.
Examples of the recording interface:

Can Acapela check the recording quality of the recordings and give feedback?
Since October 2020, there is no audio quality check anymore from Acapela.
We encourage the user to ensure the audio quality is sufficient, while the first three recordings are played back out loud (for each new recording session initiated).
What are the most important things to keep in mind to ensure a quality recording?
Here we state the most important aspects to consider for a successful recording. More details and tips are provided in the rest of the FAQ.
- Use a headset microphone to keep the mouth-to-microphone distance constant throughout the recording, and use the same microphone for the entire recording.
- If possible, make all the recordings in the same room in order to maintain a constant acoustic and background noise during the whole recording.
- Always use the calibrate function before each session.
- Speak normally in a relaxed way, do not over-articulate or use exaggerated intonations.
- After pausing the recording, listen to some of the previous recordings before starting with new ones, to make sure you continue with a similar tone and intonation.
- Take pauses whenever you feel tired, and drink water regularly during the recordings.
What do I do if I don’t know how to pronounce a word?
Listen to the pronunciation example on the recording interface by clicking on the sentence (D):
The better your pronunciation matches the pronunciation “expected by the system, the better a TTS (Text-to-Speech) version (synthetic voice) you will get. “Stick to the punctuation in the sentence: i.e. make pauses, where there is punctuation (e.g , ; :), and avoid pauses in other places. recorded as it is.
Q: What if my accent is different from the sound example in the sentence? A: Normally a different accent even a non-native accent should not be a problem for a “correct” reproduction of your voice as it is, as long as you are more or less consistent in the difference to the main accent. Some differences, affecting the order of sounds may turn out more disruptive than inherent sound characteristics : such as e.g.
- pronouncing intrusive sounds in English “law-r-an-order”.
- or choosing a different variant pronunciation than the one assumed by the system (e.g. often : [O1 f @ n ] vs. [O1 f t @ n ]).
- Such intrusive/reordered sounds might inadvertently show up in the resulting synthesis in places where you do not expect them.
If you are not sure about how to pronounce a chain of sounds or a word in a sentence, listen to the pronunciation example for the sentence and copy it.
How can I access text-to-speech demo after the recordings?
After the recordings, the user will have access to the online demo version of text-to-speech (TTS) through the personal login on My-Own-Voice website. An example of the page is shown below.
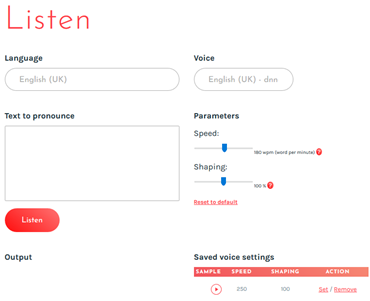
Note that you can adjust your voice (speed, voice shape) and then save the custom settings. In such way, you could have those settings used once you purchase or get your voice throughout a partner program.
What is the best way to test my voice in the demo?
For a more realistic test we recommend testing the demo using the speaker and not the headphones, as this will be the way the product will be used. We also encourage testing using portable units like tablet, smartphones and other internet-connected devices to get as close as possible to the real experience when testing the voice via the demo.
What is next ? How do I use my voice on a Speech Generating Device (SGD) ?
Once you have tested your voice online with the type & talk demo (free of charge), you can purchase your voice and use it offline in a specific hardware or software (application).
You can purchase your voice directly through Acapela or via a third party (partner, reseller, a national health insurance program or other).
Your voice can be delivered in different formats including Windows, iOS or Android.
Once the process is completed, you will receive a link to download your voice as a package.
Following are the details :
· For Windows : you will receive a SAPI version of your voice with instructions on how to install it as a built-in system voice. The voice can be then be used with a SAPI compatible device.
· For iOS : your voice will be created in an iOS version and uploaded to our Acapela Voice Server (AVS) My-Own-Voice.
Since October 2023, My-Own-Voice is installed as a system voice on any iOS-based device. Any application that is able to list the synthetic voices installed on a device will be automatically compatible. There are still some partners’ applications that offer the option to install a My-Own-Voice from their own application’s settings.
More information available on https://mov.acapela-group.com/acapelamov/
Either way, you will need to fill in your My-Own-Voice credentials in order to retrieve your voice.
· For Android : your voice can be installed as a built-in system voice (built-in – similar to a SAPI voice on a Windows operating system). To install a voice, you will need to use the Acapela TTS Voice app on Playstore. Please check the guidelines here.
Do you keep the material uploaded for message banking forever?
The material uploaded by each voice created is stored and used only during the creation process. All materials are deleted from our servers once the voice is created and is made available for listening online. It is the user’s responsibility to ensure that the material uploaded is backed up and saved properly.
How long do you keep the recordings and the voice that was created?
Information about personal data, recordings and other are mentioned in the General Data Protection Regulation (GDPR) section of our Terms of Service.
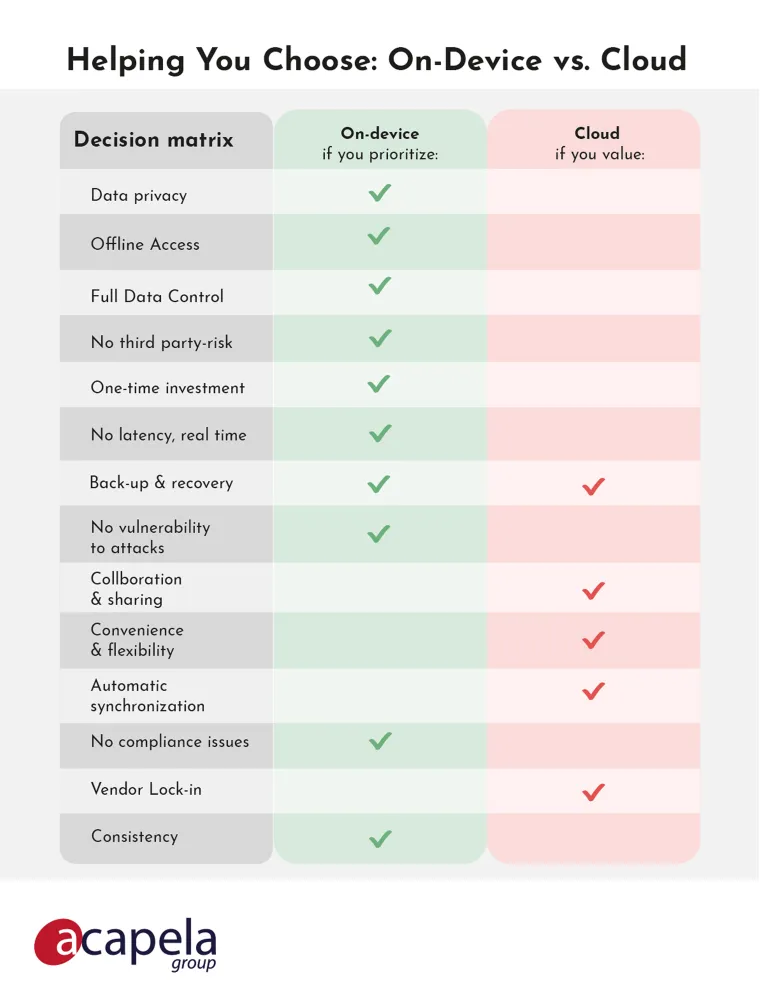
Voice Preservation: Your Voice, Your Privacy.
On-Device or in the Cloud? Your Choice Matters When Preserving Your AI Voice — Especially for Privacy. Learn Why.
Voice preservation, or voice banking, uses Artificial Intelligence to create a digital replica of your voice. By recording 50 phrases, you can preserve its essence.
Services like My-own-voice from Acapela Group let you create your synthetic voice from home with a device (PC or mobile app) and internet. This technology helps maintain your identity and ensures your voice stays with you, even in case of voice loss. With a focus on privacy and security,
More Than Just Your Voice
On-device solutions are the best way to keep your data private, secure, and fully under your control while interacting with your environment. Acapela Group keeps your voice data safe, giving you control over your voice’s legacy.
Complete Control Over Your Voice & Data
 |
Your voice and personal data stay secure with My-Own-Voice by Acapela Group. Our voice preservation technology keeps your data on your device—giving you full control and privacy—unlike cloud services that don’t guarantee ownership. Your voice is protected directly on your device for peace of mind. |
Data Privacy and Security
 |
With local storage, your data is entirely under your control. Your voice and personal details remain private, ensuring that sensitive information like credit card numbers and Social Security data is kept secure and protected from unauthorized access or interception. Your privacy is our priority. |
No Third-Party Access
 |
Acapela Group prioritizes your privacy by keeping your personal data safe from prying eyes. Our on-device solution ensures that your information remains completely private and is never exposed to third-party providers. With us, you can trust that your data won’t be shared, sold, or accessed without your permission. |
No Internet. No Problem.
 |
Your voice will talk anytime, regardless of internet connectivity. Offline access is especially crucial for ensuring the perfect use of your assistive communication solutions at any time, even in areas with unstable or no internet and guarantee the use of your voice anytime you need it. |
No additional Subscription Fees
 |
With Acapela Group, there are no hidden fees -just one-time costfor a reliable voice preservation solution. By using an on-device approach, you avoid the ongoing subscription fees typically tied to cloud services. You only pay for your voice, making your investment simple, predictable, and hassle-free. One and done. |
How to get complete information about the product?
The FAQ on this page is mostly concerned with technical aspects of the recording, for a complete production description please visit the learn more page of the My-Own-Voice website.